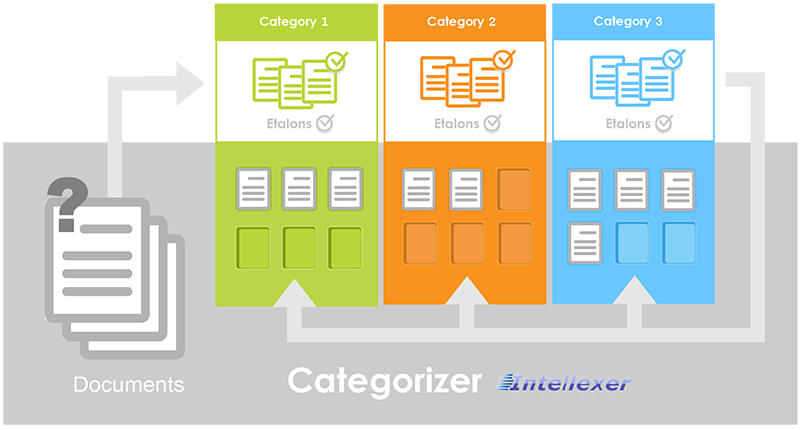
Intellexer Categorizer can be easily integrated into custom Document/Knowledge management systems using programming languages C/C++ and C#. Our SDK contains all necessary include files and import libraries for binding user applications with Categorizer module.
Here is a C++ example of how to add Intellexer Categorizer to your application:
#include <iostream>
#include <CategoryManager.h>
#include <IndexManager.h>
#include <Indexer.h>
#include <ComparatorInt.h>
#include <CategorizerLib.h>
#include <LPXml.h>
#include <LRCore.h>
using std::cout;
using std::cerr;
using std::endl;
using namespace NsSemSDK;
// provide access to category data
class CCategoryInfo : public NsSemSDK::ICategory
{
public:
// Initializing/cleaning
CCategoryInfo(void) {}
virtual ~CCategoryInfo(void) {}
// realization of ICategory interface
virtual int GetID() const
{ return m_nCatID; }
virtual const char* GetName() const
{ return m_sName.c_str(); }
virtual const char* GetDescription() const
{ return m_sDescription.c_str(); }
virtual const char* GetSpecialInfo() const
{ return m_sName.c_str(); }
virtual int GetParentID() const
{ return 0; }
// realization of IDestuctible interface
virtual void Destroy() throw()
{ delete this; }
// Accessories
void SetName(const char* pszName)
{ m_sName = pszName; }
void SetDescription(const char* pszDescription)
{ m_sDescription = pszDescription; }
protected:
std::string m_sName;
std::string m_sDescription;
int m_nCatID;
};
const char* g_szCategoryName1 = "Audio system";
const char* g_pszCategoryDescription1 = "Description of different innovation in audio systems (audio centers, tape recoders and so on)";
const char* g_arCategoryFiles1[] =
{
"../Data/Categorizer/AudioSystem/6,678,380.htm",
"../Data/Categorizer/AudioSystem/6,684,060.htm",
"../Data/Categorizer/AudioSystem/6,721,427.htm",
"../Data/Categorizer/AudioSystem/6,744,898.htm",
"../Data/Categorizer/AudioSystem/6,747,678.htm"
};
const char* g_szCategoryName2 = "Sport Equipment";
const char* g_pszCategoryDescription2 = "Description of some new ideas in implementing some sport equipment (snowboard, bike)";
const char* g_arCategoryFiles2[] =
{
"../Data/Categorizer/SportEquipment/5586702.htm",
"../Data/Categorizer/SportEquipment/6053513.htm",
"../Data/Categorizer/SportEquipment/6093767.htm",
"../Data/Categorizer/SportEquipment/6223350.htm",
"../Data/Categorizer/SportEquipment/6488308.htm"
};
int main(int argc, char* argv[])
{
std::string sFileName("../Data/Categorizer/6,647,121.htm"); // path to source document
if (argc == 2)
{
sFileName = argv[1];
}
try
{
char szDBPath[] = "../../LDB"; //path to ldb
char szLPluginsPath[] = "../../LPlugins"; //path to plugins
CCategoryInfo oCategory;
int nCategoryID;
int nDocumentID;
int i;
// provide path to license file
SetCategorizerLicensePath("../../ISDK_License.xml");
SetLPXMLLicensePath("../../ISDK_License.xml");
SetLanguageRecognizerLicensePath("../../ISDK_License.xml");
// ****** Create Category Database *******
// load linguistic database for processing documents by indexer
cerr << "Loading database... \t";
CInterfacePtr<IIndexerDB> pIndexerDB(LoadIndexerDB(szDBPath, szLPluginsPath));
cerr << "done\n";
// Create Indexer.
CInterfacePtr<IIndexer> pIndexer(CreateIndexer(*pIndexerDB));
// Create Category DB using FireBird DB provider (FBCategoryDriver).
CInterfacePtr<ICategoryManager> pCategoryManager((ICategoryManager *)CreateProvider("FBCategoryDriver", "CreateCategoryManager"));
pCategoryManager->Open("../Data/Categorizer/Category.FDB");
pCategoryManager->Clear();
// add category "Audio system"
cerr << "Add category: Audio system" << std::endl;
oCategory.SetName(g_szCategoryName1);
oCategory.SetDescription(g_pszCategoryDescription1);
nCategoryID = pCategoryManager->AddCategory(&oCategory);
// add model documents to category
for (i = 0; i < 5; ++i)
{
CInterfacePtr<IDocumentIndex> piDoc;
pIndexer->Process(g_arCategoryFiles1[i], &piDoc);
nDocumentID = pCategoryManager->AddDocument(piDoc.Get());
pCategoryManager->AddModelDocument(nCategoryID, nDocumentID);
}
// add category "Sport Equipment"
cerr << "Add category: Sport Equipment" << std::endl;
oCategory.SetName(g_szCategoryName2);
oCategory.SetDescription(g_pszCategoryDescription2);
nCategoryID = pCategoryManager->AddCategory(&oCategory);
// add model documents to category
for (i = 0; i < 5; ++i)
{
CInterfacePtr<IDocumentIndex> piDoc;
pIndexer->Process(g_arCategoryFiles2[i], &piDoc);
nDocumentID = pCategoryManager->AddDocument(piDoc.Get());
pCategoryManager->AddModelDocument(nCategoryID, nDocumentID);
}
// ****** Categorize user document *******
// Create Categorizer
CInterfacePtr<ICategorizer> pCategorizer (CreateCategorizer(pIndexerDB.Get(), pCategoryManager.Get(), EProximityAlgMax, EFindSimilarAlgStd));
// Categorize user document
CInterfacePtr<IEnumCategoryProximity> pEnumCategoryProximity(pCategorizer->Categorize(sFileName.c_str()));
int nID = 0;
double dProximity = 0.0;
while (pEnumCategoryProximity->Next(&nID, &dProximity))
{
CInterfacePtr<ICategory> pCategory(pCategoryManager->GetCategory(nID));
cout << nID << "\t" << pCategory->GetName() << "\t" << dProximity << std::endl;
}
pCategoryManager->Close();
}
catch (const CSemBaseException& x)
{
// Handle exceptions.
cerr << x.what();
}
return 0;
}
As a result, all user documents will be classified into an appropriate category.